반응형
지난 게시글에 이어 오늘은 Relu함수와 Optimizer에 대해 공부해보려고 한다.
자세한 내용은 생략하고 코드로 보자~!
1). 데이터셋 가져오기, 훈련세트, 테스트세트, 검증세트로 나누기
from tensorflow import keras
(train_input, train_target), (test_input,test_target) = keras.datasets.fashion_mnist.load_data()
from sklearn.model_selection import train_test_split
train_scaled = train_input/255.0
train_scaled = train_input.reshape(-1,28*28)# -1 : 첫번째 차원은 그대로두고 나머지 차원만 바꾼다.
train_scaled, val_scaled, train_target, val_target = train_test_split(train_scaled,train_target,test_size=0.2,random_state=42)2). 모델 만들기
#출력층을 마지막에 꼭 둬야한다.
model=keras.Sequential()
model.add(keras.layers.Dense(100, activation='sigmoid',input_shape=(784,)))
model.add(keras.layers.Dense(10, activation='softmax'))
model.summary()
print(train_target)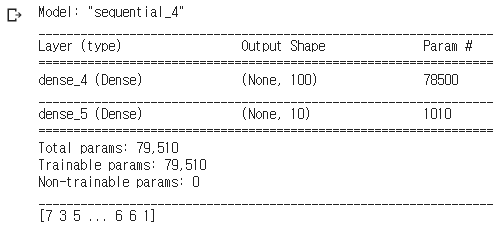
- Dense-1 : 뉴런 100개 sigmoid 활성화 함수 적용 / 784픽셀
- Dense-2 : 뉴런 10개 softmax 활성화 함수 적용
3). 훈련
model.compile(loss='sparse_categorical_crossentropy', metrics='accuracy')
model.fit(train_scaled,train_target, epochs=5)- sparse_categorical_crossentropy => 손실함수 적용 : 원-핫 코딩으로 타깃이 준비되있어야한다.
- 훈련횟수 = 5회

4). 모델 변경 : sigmoid => relu
model = keras.Sequential()
model.add(keras.layers.Flatten(input_shape=(28,28)))
model.add(keras.layers.Dense(100,activation='relu'))
model.add(keras.layers.Dense(10,activation='softmax'))
model.summary()
- Flatten : 기존에는 인공신경망에 주입하기 위해 Numpy의 reshape함수를 이용하여 1차원으로 데이터를 변환하였지만, keras에서 제공하는 함수로 1차원으로 변경하였다.
- sigmoid를 적용했던 Dense-1층을 relu함수로 변경
- sigmoid는 함수그래프를 보면 끝과 끝으로 갈수록 그래프가 누워있어 정확한 출력을 만드는데 빠르지 못하다. 이런 부분을 개선하기 위해 relu함수를 적용한다.
Relu함수란?
- 입력이 양수일 경우 활성화함수가 없는 것 처럼 데이터를 통과시키고, 음수면 0으로 만든다.
5). 다시 훈련데이터 준비 및 변경한 모델 실행
#다시 데이터 준비해서 지금 만든 모델을 훈련시켜보자.
(train_input, train_target), (test_input,test_target) = keras.datasets.fashion_mnist.load_data()
train_scaled = train_input/255.0
train_scaled = train_input.reshape(-1,28*28)# -1 : 첫번째 차원은 그대로두고 나머지 차원만 바꾼다.
train_scaled, val_scaled, train_target, val_target = train_test_split(train_scaled,train_target,test_size=0.2,random_state=42)
model.compile(loss='sparse_categorical_crossentropy', metrics='accuracy')
model.fit(train_scaled,train_target, epochs=5)
=> 조금더 성능이 좋아진것을 확인 할 수 있다.
6). 검증
model.evaluate(val_scaled,val_target)
loss가 왜이렇게 높지...? 따로, 알아봐야겠다...
7). 옵티마이저 적용
##1 확률적 경사하강법
sgd = keras.optimizers.SGD()
model.compile(optimizer=sgd, loss='sparse_categorical_crossentropy', metrics='accuracy')
#확률적 경사하강법 사용시 learning_rate 설정하는방법
#sgd = keras.optimizers.SGD(learning_rate=0.1)
#네스테로프 모멘텀 사용시 => 확률적 경사하강법 보다 더 좋은 성능을 낸다고 한다.
sgd = keras.optimizers.SGD(momentum=0.9,nesterov=True)
#다른 적응적 학습률을 사용하는 옵티마이저
##2. adagrad
adagrad = keras.optimizers.Adagrad()
model.compile(optimizer=adagrad, loss='sparse_categorical_crossentropy', metrics='accuracy')
##3. rmsprop
adagrad = keras.optimizers.Adagrad()
model.compile(optimizer=adagrad, loss='sparse_categorical_crossentropy', metrics='accuracy')8). 옵티마이저를 적용하고, 다시 모델을 만들어준다.
model = keras.Sequential()
model.add(keras.layers.Flatten(input_shape=(28,28)))
model.add(keras.layers.Dense(100,activation='relu'))
model.add(keras.layers.Dense(10,activation='softmax'))8). 옵티마이저를 적용하고, 다시 모델을 만들어준다.9). 다시 훈련해보자
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy',metrics='accuracy')
model.fit(train_scaled,train_target,epochs=5)
성능은 조금더 나아졌다.
검증도 한번 해보자
10). 재검증
model.evaluate(val_scaled,val_target)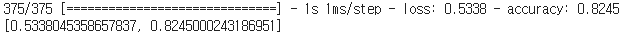
후하 문제없이 끝났다.
성능도 괜찮게 나왔고, 손실도 적게 나온것 같다....?;
여기까지..!
반응형
'AI > Deep Learning' 카테고리의 다른 글
| [Tensorflow 2.x / Keras] 기본 -2 패션 MNIST 데이터 셋 활용 / 인공신경망-2 / 다층 (0) | 2021.01.20 |
|---|---|
| [Tensorflow 2.x / Keras] 기본 -1 패션 MNIST 데이터 셋 활용 / 인공신경망-1 /단층 (0) | 2021.01.20 |
| [Tensorflow2.x] CheckPoint란? (0) | 2021.01.14 |
| [Tensorflow2.x] Linear Regression(선형회귀) 란? (0) | 2021.01.14 |
| [Tensorflow2.x / Keras] 손글씨 숫자 분류를 위한 신경망 만들기 (0) | 2021.01.11 |