반응형
물고기 종류 2가지의 데이터(무게,길이)를 학습시키고, 새로운 무게,길이 데이터를 입력했을 때 결과 예측하는 코드를 짜보자.
환경 : Colab
1). 물고기 데이터 입력

2). matplotlib를 통해 그래프로 표현
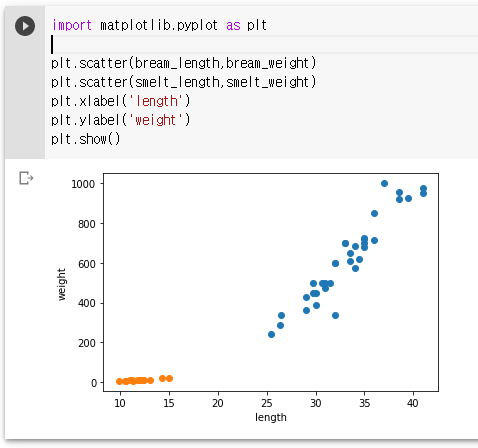
3). 리스트 두개를 하나로 합친다.
bream 데이터 + smelt 데이터 => 이유? 학습시킬 데이터를 하나로 묶어 표현하기 위함

4). 사이킷 런 패키지를 사용하기 위해 length와 weight를 2차원 데이터로 묶어준다.

5). 우리는 찾고싶은 데이터를 기준으로 1, 나머지는 0으로 기준을 잡을 것이다.
1,0으로 구분하는것은 컴퓨터 기준으로 표현하기 위함이다.

6). KNeightborsClassifiler 사용
k-최근접 알고리즘으로, 입력된 데이터를 다른 데이터들에 대입하여 다수를 차지하는 것을 정답으로 하는 알고리즘이다.

결과 => 1.0 == 100% 기본 neighbor(근접데이터갯수)5개일 경우 100% 정확도라고 볼수있다.
훈련이 잘되었다. 그럼 결과를 예측해보자

7). 근접데이터 갯수를 49개 모든 물고기 데이터의 갯수로 지정해서 결과를 확인해 보자

결과값 0.71...은 결국 35/14 의 값이다.
여기서 왜 35인 bream 으로 계산이되나?
fish_data에 49개의 데이터중 다수를 차지하는게 bream(35개)이기 때문에 다수를 차지하는것 기준으로 에측값이 나온다.
8). 다시 예측값 확인
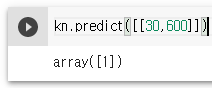
똑같이 1을 반환하여 bream이라는것을 확인 할 수 있다.
반응형
'AI > Machine Learning' 카테고리의 다른 글
| [Python] 머신러닝 기초-5 선형회귀(Linear Regression) 알고리즘을 통한 연습 / 선형회귀란? 다항회귀란? (0) | 2021.01.18 |
|---|---|
| [Python] 머신러닝 기초-4 K-Neighbors (최근접)알고리즘을 통한 연습- 회귀 (0) | 2021.01.18 |
| [Python] 머신러닝 기초-3 K-Neighbors (최근접)알고리즘을 통한 연습- 분류 (0) | 2021.01.15 |
| [Python] 머신러닝 기초-2 K-Neighbors (최근접)알고리즘을 통한 연습- 분류 (0) | 2021.01.15 |
| [Python] 머신러닝 Scikit-learn(사이킷런) 사용하기 (0) | 2021.01.11 |